Usage¶
Minimal example¶
The package is designed as a library. Here is a minimal example of what you can
do (examples/example_api_minimal.py):
#!/usr/bin/python3
# Minimal example. Use the convenience function io.get_image_data() without any
# extra arguments.
from imagecluster import calc, io as icio, postproc
# The bottleneck is calc.fingerprints() called in this function, all other
# operations are very fast. get_image_data() writes fingerprints to disk and
# loads them again instead of re-calculating them.
images,fingerprints,timestamps = icio.get_image_data('pics/')
# Run clustering on the fingerprints. Select clusters with similarity index
# sim=0.5.
clusters = calc.cluster(fingerprints, sim=0.5)
# Create dirs with links to images. Dirs represent the clusters the images
# belong to.
postproc.make_links(clusters, 'pics/imagecluster/clusters')
# Plot images arranged in clusters.
postproc.visualize(clusters, images)
Have a look at the clusters, represented as dirs with symlinks to the relevant
files (by make_links()).
$ tree pics/imagecluster/clusters
pics/imagecluster/clusters
├── cluster_with_2
│ ├── cluster_0
│ │ ├── 140700.jpg -> /path/to/pics/140700.jpg
│ │ └── 140701.jpg -> /path/to/pics/140701.jpg
│ ├── cluster_1
│ │ ├── 140100.jpg -> /path/to/pics/140100.jpg
│ │ └── 140101.jpg -> /path/to/pics/140101.jpg
│ ├── cluster_2
│ │ ├── 140600.jpg -> /path/to/pics/140600.jpg
│ │ └── 140601.jpg -> /path/to/pics/140601.jpg
│ ├── cluster_3
│ │ ├── 140400.jpg -> /path/to/pics/140400.jpg
│ │ └── 140401.jpg -> /path/to/pics/140401.jpg
│ ├── cluster_4
│ │ ├── 140000.jpg -> /path/to/pics/140000.jpg
│ │ └── 140001.jpg -> /path/to/pics/140001.jpg
│ ├── cluster_5
│ │ ├── 140501.jpg -> /path/to/pics/140501.jpg
│ │ └── 140502.jpg -> /path/to/pics/140502.jpg
│ ├── cluster_6
│ │ ├── 140300.jpg -> /path/to/pics/140300.jpg
│ │ └── 140301.jpg -> /path/to/pics/140301.jpg
│ └── cluster_7
│ ├── 140200.jpg -> /path/to/pics/140200.jpg
│ └── 140201.jpg -> /path/to/pics/140201.jpg
└── cluster_with_3
└── cluster_0
├── 140801.jpg -> /path/to/pics/140801.jpg
├── 140802.jpg -> /path/to/pics/140802.jpg
└── 140803.jpg -> /path/to/pics/140803.jpg
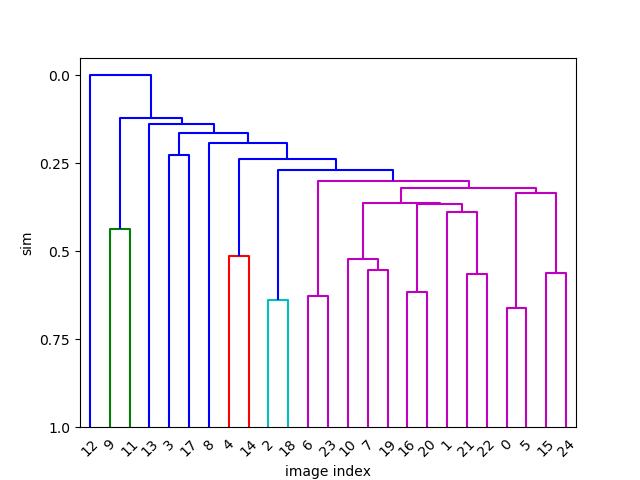
Here is a visual representation made by visualize().

So there are some clusters with 2 images each, and one with 3 images.
For this example, we use a very small subset of the Holiday image dataset (25 images (all named 140*.jpg) of 1491 total images in the
dataset). See examples/inria_holiday.sh for how to select such a subset:
#!/bin/sh
# select 25 images
# ./this.sh jpg/100*
#
# select 274 images
# ./this.sh jpg/10*
if ! [ -d jpg ]; then
for name in jpg1 jpg2; do
wget ftp://ftp.inrialpes.fr/pub/lear/douze/data/${name}.tar.gz
tar -xzf ${name}.tar.gz
done
fi
mkdir -p pics
rm -rf pics/*
for x in $@; do
f=$(echo "$x" | sed -re 's|jpg/||')
ln -s $(readlink -f jpg/$f) pics/$f
done
echo "#images: $(ls pics | wc -l)"
$ /path/to/imagecluster/examples/inria_holiday.sh jpg/140*
Here is the result of using a larger subset of 292 images from the same dataset
(inria_holiday.sh jpg/14*):

You may have noticed that in the 25-image example above, only 19 out of 25 images are
put into clusters. The others are not assigned to any cluster. Technically they
are in clusters of size 1, which we don’t report by default (unless you use
calc.cluster(..., min_csize=1)). One can now start to lower sim to find
a good balance of clustering accuracy and the tolerable amount of dissimilarity
among images within a cluster. See Clustering and similarity index.
Detailed example¶
This example shows all low-level functions and also shows how to use time
distance scaling. Use the latter if you (i) find that pure content-based
clustering throws similar but temporally uncorrelated images in the same cluster
and (ii) you have meaningful timestamp data such as EXIF tags or correct file
timestamps (watch out for those when copying files around, use cp -a or
rsync -a). See Content and time distance.
#!/usr/bin/python3
# Detailed API example. We show which functions are called inside
# get_image_data() (read_images(), get_model(), fingerprints(), pca(),
# read_timestamps()) and show more options such as time distance scaling.
from imagecluster import calc, io as icio, postproc
##images,fingerprints,timestamps = icio.get_image_data(
## 'pics/',
## pca_kwds=dict(n_components=0.95),
## img_kwds=dict(size=(224,224)))
# Create image database in memory. This helps to feed images to the NN model
# quickly.
images = icio.read_images('pics/', size=(224,224))
# Create Keras NN model.
model = calc.get_model()
# Feed images through the model and extract fingerprints (feature vectors).
fingerprints = calc.fingerprints(images, model)
# Optionally run a PCA on the fingerprints to compress the dimensions. Use a
# cumulative explained variance ratio of 0.95.
fingerprints = calc.pca(fingerprints, n_components=0.95)
# Read image timestamps. Need that to calculate the time distance, can be used
# in clustering.
timestamps = icio.read_timestamps('pics/')
# Run clustering on the fingerprints. Select clusters with similarity index
# sim=0.5. Mix 80% content distance with 20% timestamp distance (alpha=0.2).
clusters = calc.cluster(fingerprints, sim=0.5, timestamps=timestamps, alpha=0.2)
# Create dirs with links to images. Dirs represent the clusters the images
# belong to.
postproc.make_links(clusters, 'pics/imagecluster/clusters')
# Plot images arranged in clusters and save plot.
fig,ax = postproc.plot_clusters(clusters, images)
fig.savefig('foo.png')
postproc.plt.show()